Fitting gobal epistasis models with experimental “noise”¶
The global epistasis models described by Otwinoski et al (2018) fits experimentally measured functional scores for the variants using a Gaussian-likelihood function that assumes that deviations from the models are normally distributed (see the globalepistasis module documentation for more details). Those models also accommodate estimates of the noise for each functional score measurement, which are easy to make if the noise is due to statistical processes that are simple to model (such as finite sequencing depth leading to sampling statistics in the deep sequencing counts).
But often real deep mutational scanning experiments have other sources of experimental “noise.” For instance, the sequencing used to determine the mutations present in a variant might occassionally wrong, leading to mis-calling of variant sequences. Or (more commonly in Bloom lab influenza virus experiments) there may be experimental bottlenecks in the number of variants that are passaged from the pre-selection to post-selection conditions. In this last case, the noise occurs when the bottleneck randomly influences which pre-selection variants get a “chance” to go to the post-selection condition, not in the sequencing counts estimating the pre- and post-selection frequencies.
When there are bottlenecks or other noise, the Gaussian likelihoods may no longer be a good way to fit the data. Therefore, the global epistasis models allow two other ways to compute the likelihoods. These likelihood calculation methods are described in the likelihood calculation section of the globalepistasis module. Briefly, they are:
The “bottleneck” likelihood, which explicitly models a bottleneck between the pre- and post-selection conditions. You should use this likelihood when there is a bottleneck at this step that is substantially smaller than the total sequencing depth, and which you think contributes most of the “noise” in the experiment.
The Cauchy likelihood, which is like the Gaussian likelihood but has a “fatter tail” and so is less affected by outliers.
Below, we demonstrate these different likelihood calculation methods on simulated data.
Setup for analysis¶
Import Python modules / packages:
[1]:
import collections
import itertools
import random
import tempfile
import time
import warnings
import binarymap
import pandas as pd
from plotnine import *
import numpy
import dms_variants.bottlenecks
import dms_variants.codonvarianttable
import dms_variants.globalepistasis
import dms_variants.plotnine_themes
import dms_variants.simulate
from dms_variants.constants import CBPALETTE, CODONS_NOSTOP
Set parameters that define the simulated data. We want to simulate some of the samples with a lot of “noise.” Here that noise takes the form of a very tight bottleneck when transferring the pre-selection library to the selection (such bottlenecks are unavoidable in some experiments). Specifically, we simulate experiments with: - A loose bottleneck: the diversity of the pre-selection library is effectively transferred to the post-selection condition, meaning there is low “noise” from bottlenecking. - A mid bottleneck: there is a moderate bottleneck in transferring the pre-selection library to the post-selection condition, meaning there is appreciable “noise” from bottlenecking. - A tight bottleneck: there is a very narrow bottleneck when transferring the pre-selection library to the post-selection condition, leading to lots of “noise” from bottlenecking.
The exact simulation parameters are defined below:
[2]:
seed = 1 # random number seed
genelength = 40 # gene length in codons
libs = ["lib_1"] # distinct libraries of gene
variants_per_lib = 500 * genelength # variants per library
avgmuts = 2.0 # average codon mutations per variant
bclen = 16 # length of nucleotide barcode for each variant
variant_error_rate = 0.005 # rate at which variant sequence mis-called
avgdepth_per_variant = 100 # average per-variant sequencing depth
lib_uniformity = 3 # uniformity of library pre-selection
noise = 0.01 # random noise in selections
bottlenecks = { # bottlenecks from pre- to post-selection
"tight_bottle": variants_per_lib,
"mid_bottle": variants_per_lib * 3,
"loose_bottle": variants_per_lib * 50,
}
Seed random number generator for reproducible output:
[3]:
random.seed(seed)
Set pandas display options to show large chunks of Data Frames in this example:
[4]:
pd.set_option("display.max_columns", 20)
pd.set_option("display.width", 500)
Hide warnings that clutter output:
[5]:
warnings.simplefilter("ignore")
Set the gray grid plotnine theme defined in dms_variants.plotnine_themes as this gives a nice appearance for the plots:
[6]:
theme_set(dms_variants.plotnine_themes.theme_graygrid())
Simulate library of variants¶
Simulate a library of codon variants of the gene.
Simulate wildtype gene sequence:
[7]:
geneseq = "".join(random.choices(CODONS_NOSTOP, k=genelength))
print(f"Wildtype gene of {genelength} codons:\n{geneseq}")
Wildtype gene of 40 codons:
AGATCCGTGATTCTGCGTGCTTACACCAACTCACGGGTGAAACGTGTAATCTTATGCAACAACGACTTACCTATCCGCAACATCCGGCTGATGATGATCCTACACAACTCCGACGCTAGT
Generate a CodonVariantTable using simulate_CodonVariantTable function:
[8]:
variants = dms_variants.simulate.simulate_CodonVariantTable(
geneseq=geneseq,
bclen=bclen,
library_specs={
lib: {"avgmuts": avgmuts, "nvariants": variants_per_lib} for lib in libs
},
seed=seed,
)
Plot the number of amino-acid mutations per variant:
[9]:
p = variants.plotNumMutsHistogram("aa", samples=None)
p = p + theme(panel_grid_major_x=element_blank()) # no vertical grid lines
_ = p.draw(show=True)
Average number of codon mutations per variant:
[10]:
p = variants.plotNumCodonMutsByType(variant_type="all", samples=None)
p = p + theme(panel_grid_major_x=element_blank()) # no vertical grid lines
_ = p.draw(show=True)
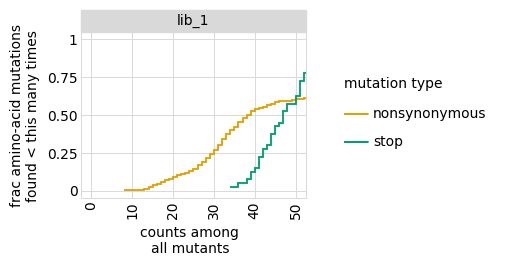
Examine how well amino-acid mutations are sampled in the library by looking at the fraction of mutations seen <= some number of times, making separate plots for single mutants and all mutants:
[11]:
for variant_type in ["single", "all"]:
p = variants.plotCumulMutCoverage(variant_type, mut_type="aa", samples=None)
_ = p.draw(show=True)
Simulate counts for samples¶
Now we simulate the counts of each variant after selection.
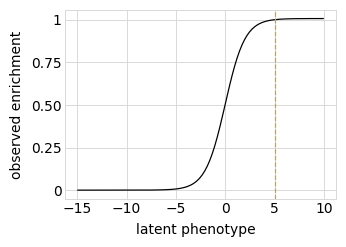
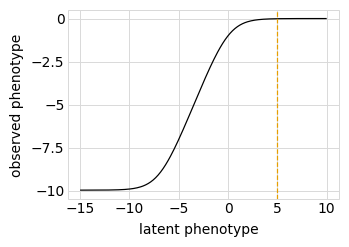
First, we define a “phenotype” function using a SigmoidPhenotypeSimulator, which follow the “global epistasis” concepts of Otwinoski et al and Sailer and Harms to define the phenotype in two steps: an underlying latent phenotype that mutations affect additively, and then an observed phenotype that is a non-linear function of the latent phenotype. The variants are then simulated according to their observed enrichments, which are the exponentials of the observed phenotypes:
[12]:
phenosimulator = dms_variants.simulate.SigmoidPhenotypeSimulator(geneseq, seed=seed)
Plot the simulated relationship of the latent phenotype with the observed enrichment and phenotype, with a dashed vertical line indicating the wildtype latent phenotype:
[13]:
for value in ["enrichment", "phenotype"]:
p = phenosimulator.plotLatentVsObserved(value)
_ = p.draw(show=True)
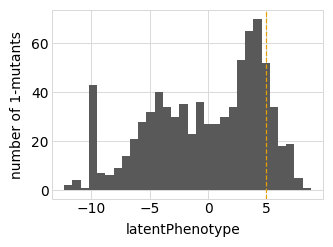
Plot the latent phenotype, observed phenotype, and observed enrichment of all single amino-acid mutants, with a dashed vertical line indicating the wildtype:
[14]:
for value in ["latentPhenotype", "observedPhenotype", "observedEnrichment"]:
p = phenosimulator.plotMutsHistogram(value)
_ = p.draw(show=True)
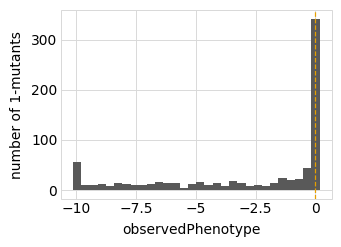
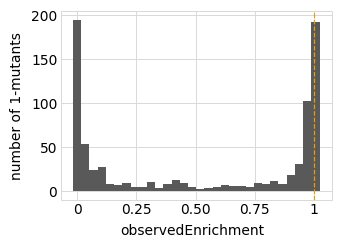
Now we use simulateSampleCounts to simulate counts of variants when selection on each variant is proportional to its observed enrichment. We simulate using the several different bottleneck sizes defined above:
[15]:
counts = dms_variants.simulate.simulateSampleCounts(
variants=variants,
phenotype_func=phenosimulator.observedEnrichment,
variant_error_rate=variant_error_rate,
pre_sample={
"total_count": variants_per_lib * avgdepth_per_variant,
"uniformity": lib_uniformity,
},
pre_sample_name="pre-selection",
post_samples={
name: {
"noise": noise,
"total_count": variants_per_lib * avgdepth_per_variant,
"bottleneck": bottle,
}
for name, bottle in bottlenecks.items()
},
seed=seed,
)
Now add the simulated counts for each library / sample to the CodonVariantTable:
[16]:
variants.add_sample_counts_df(counts)
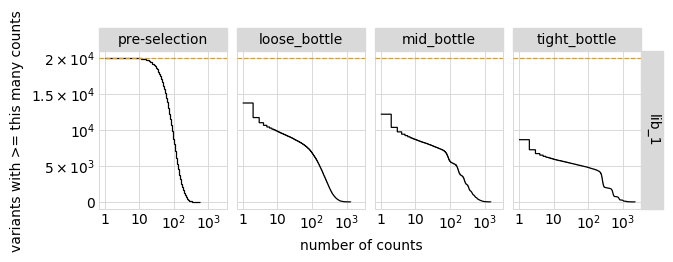
Plot the number of counts for each variant in each sample. The horizontal dashed line shows the total number of variants. The plot shows that all variants are well-sampled in the pre-selection libraries, but that post- selection some variants are sampled more or less. This is expected since selection will decrease and increase the frequency of variants:
[17]:
p = variants.plotCumulVariantCounts(orientation="v")
_ = p.draw(show=True)
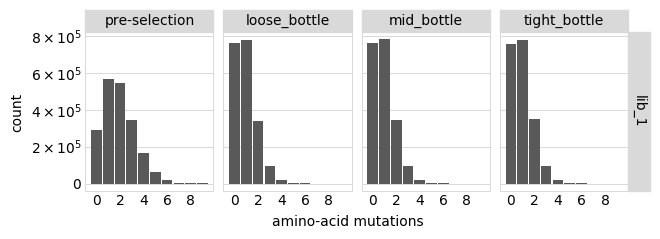
Distribution of the number of amino-acid mutations per variant in each sample. As expected, mutations go down after selection:
[18]:
p = variants.plotNumMutsHistogram(mut_type="aa", orientation="v")
p = p + theme(panel_grid_major_x=element_blank()) # no vertical grid lines
_ = p.draw(show=True)
Average number of mutations per variant:
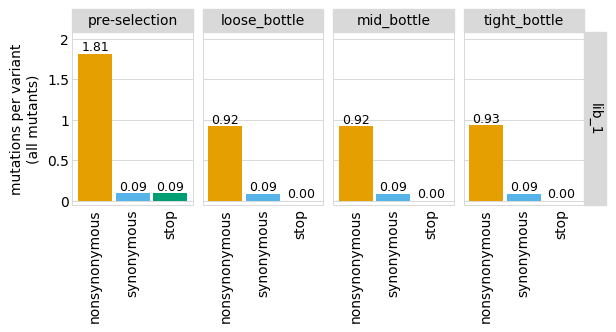
[19]:
p = variants.plotNumCodonMutsByType(variant_type="all", orientation="v")
p = p + theme(panel_grid_major_x=element_blank()) # no vertical grid lines
_ = p.draw(show=True)
Functional scores for variants¶
Use CodonVariantTable.func_scores to calculates a functional score for each variant based on its change in frequency from pre- to post-selection:
[20]:
func_scores = variants.func_scores("pre-selection", libraries=libs)
Also calculate functional scores at the level of amino-acid variants:
[21]:
aa_func_scores = variants.func_scores(
"pre-selection", by="aa_substitutions", syn_as_wt=True, libraries=libs
)
Classify variants by the “types” of mutations they have using the CodonVariantTable.classifyVariants:
[22]:
func_scores = dms_variants.codonvarianttable.CodonVariantTable.classifyVariants(
func_scores
)
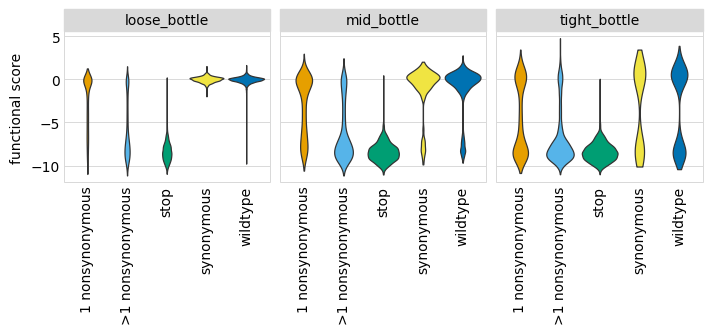
Plot the distributions of scores, coloring by the variant class. As expected, there is more noise with a tighter bottleneck, as can be seen in the spread for wildtype and stop-codon variants. This is expected, as for instance a tight bottleneck will sometimes lead to the random extinction of a wildtype variant:
[23]:
p = (
ggplot(func_scores, aes("variant_class", "func_score"))
+ geom_violin(aes(fill="variant_class"))
+ ylab("functional score")
+ xlab("")
+ facet_wrap("~ post_sample")
+ theme(
figure_size=(2.75 * len(bottlenecks), 2 * len(libs)),
axis_text_x=element_text(angle=90),
panel_grid_major_x=element_blank(), # no vertical grid lines
)
+ scale_fill_manual(values=CBPALETTE[1:])
)
_ = p.draw(show=True)
Estimate bottleneck sizes¶
In order to use the bottleneck-based likelihood, we need to know the size of the bottleneck going from the pre- to post-selection conditions. In this simulation, we know the true simulated bottleneck for each sample–but in a real experiment, we may not know the bottleneck. Therefore, we need to estimate it from the data.
We can do that if we examine just the fluctuations in frequency of the wildtype variants. The basic idea is that if there is no bottleneck, then the relative frequencies of the different wildtype variants should remain unchanged–but if there is a bottleneck then some wildtype variants will randomly go up and down in frequency compared to others. The actual calculation is implemented in the bottlenecks.estimateBottleneck function.
Below, for each sample we subset on just the wildtype variants. We then estimate the per-variant bottleneck (total bottleneck divided by number of variants), and compare it to the true values. As can be seen below, the estimates are quite accurate for narrow bottlenecks. They become less accurate for the loose bottleneck, because then the bottleneck no longer contributes much of the noise (but in this case, we also no longer really care so much about estimating the bottleneck accurately):
[24]:
# NBVAL_IGNORE_OUTPUT
estimated_bottleneck = {}
estimates = []
for sample, scores in func_scores.groupby("post_sample", observed=True):
wt_scores = scores.query("n_codon_substitutions == 0")
n = dms_variants.bottlenecks.estimateBottleneck(
wt_scores, n_pre_col="pre_count", n_post_col="post_count"
)
estimates.append((n, bottlenecks[sample] / len(scores)))
estimated_bottleneck[sample] = n * len(
scores
) # estimated total bottleneck (per variant X nvariants)
estimates_df = pd.DataFrame.from_records(estimates, columns=["estimated", "actual"])
print("Estimated and actual bottleneck per variant:")
estimates_df.round(1)
Estimated and actual bottleneck per variant:
[24]:
| estimated | actual | |
|---|---|---|
| 0 | 25.7 | 50.0 |
| 1 | 2.8 | 3.0 |
| 2 | 0.9 | 1.0 |
Confirm that the estimates are good when the bottleneck size is much smaller than the average depth per variant:
[25]:
assert numpy.allclose(
estimates_df.query("actual < 10")["actual"],
estimates_df.query("actual < 10")["estimated"],
rtol=0.1,
)
Fit global epistasis models¶
Now we fit global epistasis models using the fit_models function.
The two types of models are: - MonotonicSplineEpistasis models, which model global epistasis in the way described in Otwinoski et al (2018). - NoEpistasis models, which assume mutations contribute additively to the functional scores.
The three ways of calculating the likelihood are: - GaussianLikelihood: assumes deviations from model are normally distributed according to statistical estimates of errors in functional scores. - CauchyLikelihood: a fat-tailed distribution that is less sensitive to measurements that have large deviations from the model. - BottleneckLikelihood: explicitly models bottleneck from pre- to post-selection conditions. We use this in conjunction with the bottlenecks estimated above.
[26]:
fit_df_list = []
for sample, scores in func_scores.groupby("post_sample", observed=True):
bmap = binarymap.BinaryMap(scores)
for likelihood in ["Gaussian", "Cauchy", "Bottleneck"]:
if likelihood == "Bottleneck":
ifit_df = dms_variants.globalepistasis.fit_models(
bmap, likelihood, bottleneck=estimated_bottleneck[sample]
)
else:
ifit_df = dms_variants.globalepistasis.fit_models(bmap, likelihood)
fit_df_list.append(ifit_df.assign(sample=sample, likelihood=likelihood))
fit_df = pd.concat(fit_df_list, sort=False, ignore_index=True)
Here are the times (in seconds) that it took to fit each model:
[27]:
# NBVAL_IGNORE_OUTPUT
(
fit_df.pivot_table(
index=["likelihood", "sample"], values="fitting_time", columns="description"
).round(1)
)
[27]:
| description | global epistasis | no epistasis | |
|---|---|---|---|
| likelihood | sample | ||
| Bottleneck | loose_bottle | 22.7 | 0.4 |
| mid_bottle | 12.2 | 0.2 | |
| tight_bottle | 7.8 | 0.2 | |
| Cauchy | loose_bottle | 21.1 | 1.6 |
| mid_bottle | 13.5 | 1.0 | |
| tight_bottle | 10.3 | 0.7 | |
| Gaussian | loose_bottle | 10.6 | 0.2 |
| mid_bottle | 8.2 | 0.1 | |
| tight_bottle | 6.3 | 0.1 |
Now we want to see if the no-epistasis or global epistasis model fits the data better in each case. To do this, we compare the AIC. Models with lower AIC are better. We compute the \(\Delta\)AIC between the global epistasis model (MonotonicSplineEpistasis) and no-epistasis model (NoEpistasis): positive \(\Delta\)AIC values indicate that the global epistasis model is better. (Crucially, we can only compare models with likelihoods calculated in the same way on the same data).
Below we see that in all cases, the global epistasis model is better than the no-epistasis model:
[28]:
# NBVAL_IGNORE_OUTPUT
aic_df = (
fit_df.pivot_table(
index=["likelihood", "sample"], values="AIC", columns="description"
)
.assign(deltaAIC=lambda x: x["no epistasis"] - x["global epistasis"])[["deltaAIC"]]
.round(1)
)
assert all(aic_df["deltaAIC"] > 0), "global epistasis model not better"
aic_df
[28]:
| description | deltaAIC | |
|---|---|---|
| likelihood | sample | |
| Bottleneck | loose_bottle | 248738.2 |
| mid_bottle | 16498.1 | |
| tight_bottle | 2690.0 | |
| Cauchy | loose_bottle | 21072.1 |
| mid_bottle | 18006.7 | |
| tight_bottle | 16968.0 | |
| Gaussian | loose_bottle | 36166.7 |
| mid_bottle | 17981.2 | |
| tight_bottle | 3728.7 |
Confirm global epistasis model is always better (\(\Delta\)AIC always positive):
[29]:
assert (aic_df["deltaAIC"] > 0).all()
Because the MonotonicSplineEpistasis global epistasis model is always better than the additive NoEpistasis model, below we just analyze the results from the global epistasis model.
First, we will examine how the model fits look on all the actual variants used to fit the model. We use AbstractEpistasis.phenotypes_df to get a data frame of all the variants used to fit each global epistasis model along with their functional scores and the latent and observed phenotypes predicted by each model:
[30]:
variants_df = pd.concat(
[
tup.model.phenotypes_df.assign(sample=tup.sample, likelihood=tup.likelihood)
for tup in fit_df.itertuples()
if tup.description == "global epistasis"
],
ignore_index=True,
sort=False,
)
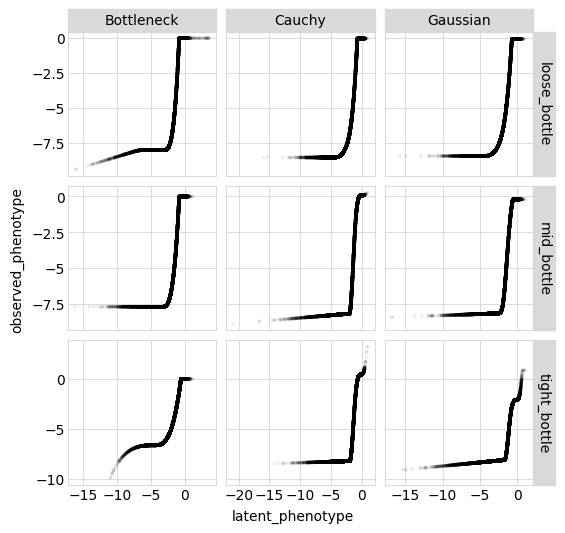
Below we plot the relationship between the observed and latent phenotype for each sample and likelihood-calculation method:
[31]:
p = (
ggplot(variants_df, aes("latent_phenotype", "observed_phenotype"))
+ geom_point(alpha=0.05, size=0.5)
+ facet_grid("sample ~ likelihood", scales="free")
+ theme(
figure_size=(
2 * variants_df["likelihood"].nunique(),
2 * variants_df["sample"].nunique(),
),
)
)
_ = p.draw(show=True)
Model vs truth for amino-acid variants¶
Because we simulated the variants, we can also use the SigmoidPhenotypeSimulator to get the true phenotype of each variant. (Obviously in real non-simulated experiments the true phenotypes are unknown.)
We want to see if the model outperforms the experiments if look at the level of amino-acid variants (meaning we pool the counts for all variants with the same amino-acid substitutions together before calculating the functional scores). Recall that above we already got such functional scores into the variable aa_func_scores:
First we get a data frame of measured functional scores (in the simulated experiment) calculated at the level of amino-acid variants (pooling all barcoded variants with the same amino-acid mutations):
[32]:
aa_variants_df = aa_func_scores.rename(columns={"post_sample": "sample"})[
["sample", "aa_substitutions", "n_aa_substitutions", "func_score"]
].assign(measured_enrichment=lambda x: 2 ** x["func_score"])
Now we add the model-predicted latent phenotype, observed phenotype, and enrichment for each amino-acid variant using the AbstractEpistasis.add_phenotypes_to_df method:
[33]:
df_list = []
for sample, df in aa_variants_df.groupby("sample", observed=True):
for likelihood in fit_df["likelihood"].unique().tolist():
model = fit_df.query(
'(likelihood == @likelihood) & (sample == @sample) & (description == "global epistasis")'
).model.values[0]
df_list.append(
model.add_phenotypes_to_df(df).assign(
predicted_enrichment=lambda x: model.enrichments(
x["observed_phenotype"]
),
likelihood=likelihood,
)
)
aa_variants_df = pd.concat(df_list, ignore_index=True, sort=False)
Now we add the “true” values from the simulator:
[34]:
aa_variants_df = aa_variants_df.assign(
true_latent_phenotype=lambda x: x["aa_substitutions"].map(
phenosimulator.latentPhenotype
),
true_enrichment=lambda x: x["aa_substitutions"].map(
phenosimulator.observedEnrichment
),
true_observed_phenotype=lambda x: x["aa_substitutions"].map(
phenosimulator.observedPhenotype
),
)
Now we calculate the correlations between the true enrichments from the simulations and the measured values and the ones predicted by the model. We do this using enrichment rather than observed phenotype as we expect the observed phenotypes to be very noisy at the “low end” (since experiments lose the sensitivity to distinguish among bad and really-bad variants):
[35]:
# NBVAL_IGNORE_OUTPUT
enrichments_corr = (
aa_variants_df.rename(
columns={
"predicted_enrichment": "model prediction",
"measured_enrichment": "measurement",
}
)
.melt(
id_vars=["sample", "likelihood", "true_enrichment"],
value_vars=["model prediction", "measurement"],
var_name="enrichment_type",
value_name="enrichment",
)
.groupby(["sample", "likelihood", "enrichment_type"])
.apply(lambda x: x["enrichment"].corr(x["true_enrichment"]))
.rename("correlation")
.to_frame()
.pivot_table(
index=["sample", "likelihood"], values="correlation", columns="enrichment_type"
)
)
enrichments_corr.round(2)
[35]:
| enrichment_type | measurement | model prediction | |
|---|---|---|---|
| sample | likelihood | ||
| loose_bottle | Bottleneck | 0.97 | 0.97 |
| Cauchy | 0.97 | 0.99 | |
| Gaussian | 0.97 | 0.99 | |
| mid_bottle | Bottleneck | 0.80 | 0.98 |
| Cauchy | 0.80 | 0.99 | |
| Gaussian | 0.80 | 0.99 | |
| tight_bottle | Bottleneck | 0.58 | 0.96 |
| Cauchy | 0.58 | 0.90 | |
| Gaussian | 0.58 | 0.76 |
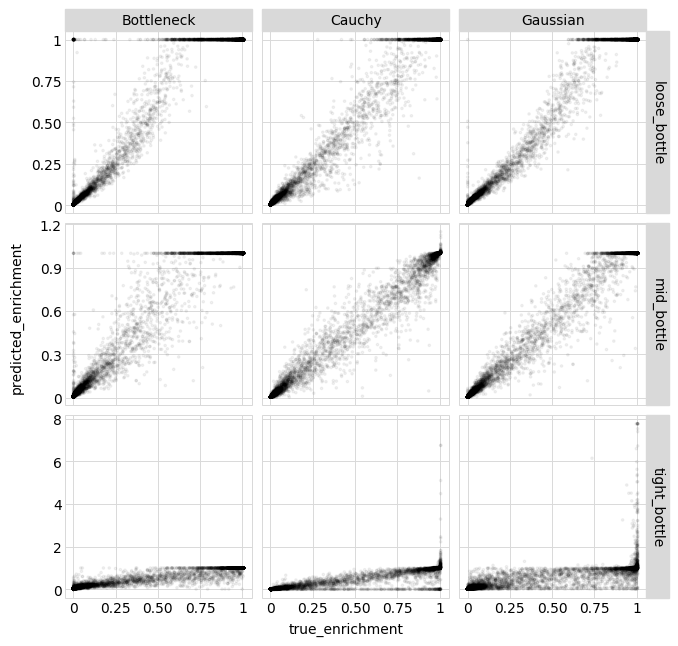
Above we see that the model predictions are always better than the actual measurements, and furthermore that when there is a very tight experimental bottleneck (lots of “noise”) the Bottleneck likelihood (and to a lesser degree the Cauchy likelihood) outperforms the Gaussian likelihood.
Below we plot the correlations between the model predictions and the true enrichments for each likelihood calculation method:
[36]:
p = (
ggplot(aa_variants_df, aes("true_enrichment", "predicted_enrichment"))
+ geom_point(alpha=0.05, size=0.5)
+ facet_grid("sample ~ likelihood", scales="free")
+ theme(
figure_size=(
2.5 * variants_df["likelihood"].nunique(),
2.5 * variants_df["sample"].nunique(),
)
)
)
_ = p.draw(show=True)
Model vs truth for single mutants¶
Now we repeat the above analysis for just single amino-acid mutants.
First, get the single amino-acid mutant variants:
[37]:
single_aa_variants_df = aa_variants_df.query("n_aa_substitutions == 1").reset_index(
drop=True
)
Tabulate how the measurements and model predictions compare to the true enrichments:
[38]:
# NBVAL_IGNORE_OUTPUT
enrichments_corr = (
single_aa_variants_df.rename(
columns={
"predicted_enrichment": "model prediction",
"measured_enrichment": "measurement",
}
)
.melt(
id_vars=["sample", "likelihood", "true_enrichment"],
value_vars=["model prediction", "measurement"],
var_name="enrichment_type",
value_name="enrichment",
)
.groupby(["sample", "likelihood", "enrichment_type"])
.apply(lambda x: x["enrichment"].corr(x["true_enrichment"]))
.rename("correlation")
.to_frame()
.pivot_table(
index=["sample", "likelihood"], values="correlation", columns="enrichment_type"
)
)
enrichments_corr.round(2)
[38]:
| enrichment_type | measurement | model prediction | |
|---|---|---|---|
| sample | likelihood | ||
| loose_bottle | Bottleneck | 0.99 | 0.98 |
| Cauchy | 0.99 | 1.00 | |
| Gaussian | 0.99 | 0.99 | |
| mid_bottle | Bottleneck | 0.91 | 0.99 |
| Cauchy | 0.91 | 1.00 | |
| Gaussian | 0.91 | 1.00 | |
| tight_bottle | Bottleneck | 0.78 | 0.98 |
| Cauchy | 0.78 | 0.92 | |
| Gaussian | 0.78 | 0.77 |
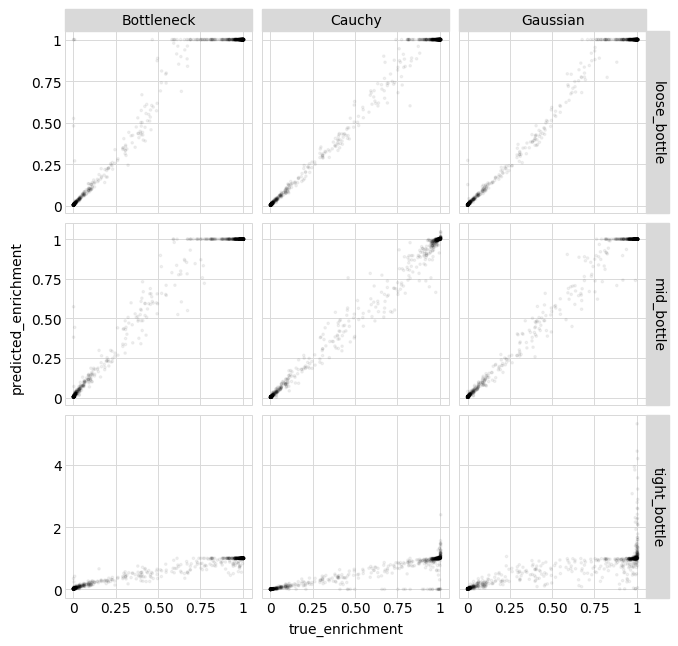
Once again, the model predictions outperform the measurements, and the Bottleneck likelihood performs best for the tight bottleneck.
Plot the predictions for each likelihood-calculation method:
[39]:
p = (
ggplot(single_aa_variants_df, aes("true_enrichment", "predicted_enrichment"))
+ geom_point(alpha=0.05, size=0.5)
+ facet_grid("sample ~ likelihood", scales="free")
+ theme(
figure_size=(
2.5 * variants_df["likelihood"].nunique(),
2.5 * variants_df["sample"].nunique(),
)
)
)
_ = p.draw(show=True)